Clarix is a Capacity & Sourcing Engine built during the Danfoss Hackathon by a 6-person team, built on a real operational dataset from Danfoss.
Technologies
Python
Streamlit
Pandas
Claude Sonnet 4.5
Gemini 2.5 Flash
MRP
Scenario Simulation
The Challenge
Given a large portfolio of active projects competing for shared manufacturing capacity, there was no single tool that unified capacity utilisation, scenario simulation, bottleneck detection, and MRP. Planners had to piece together information from multiple systems.
The Solution
Clarix consolidates this into five Streamlit pages, each addressing a distinct operational concern:
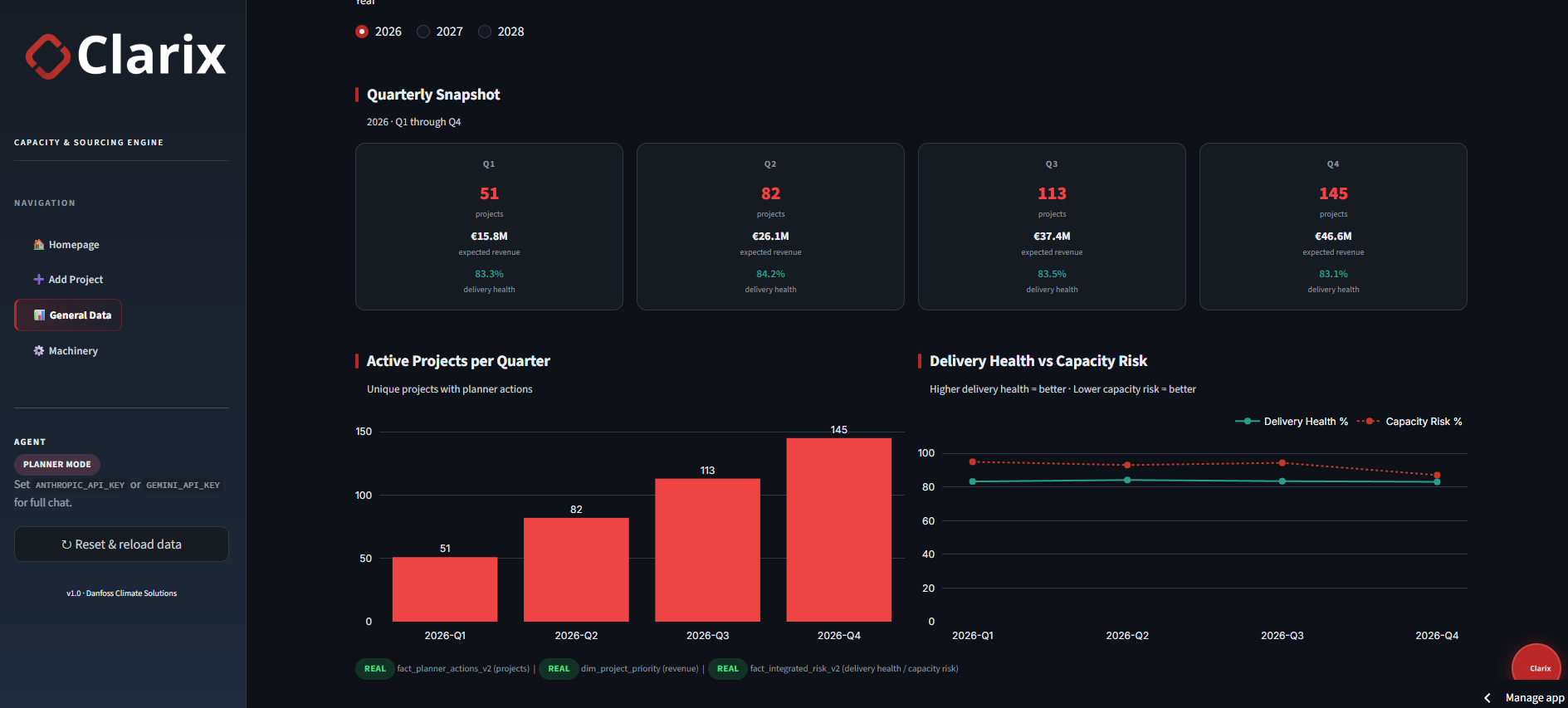
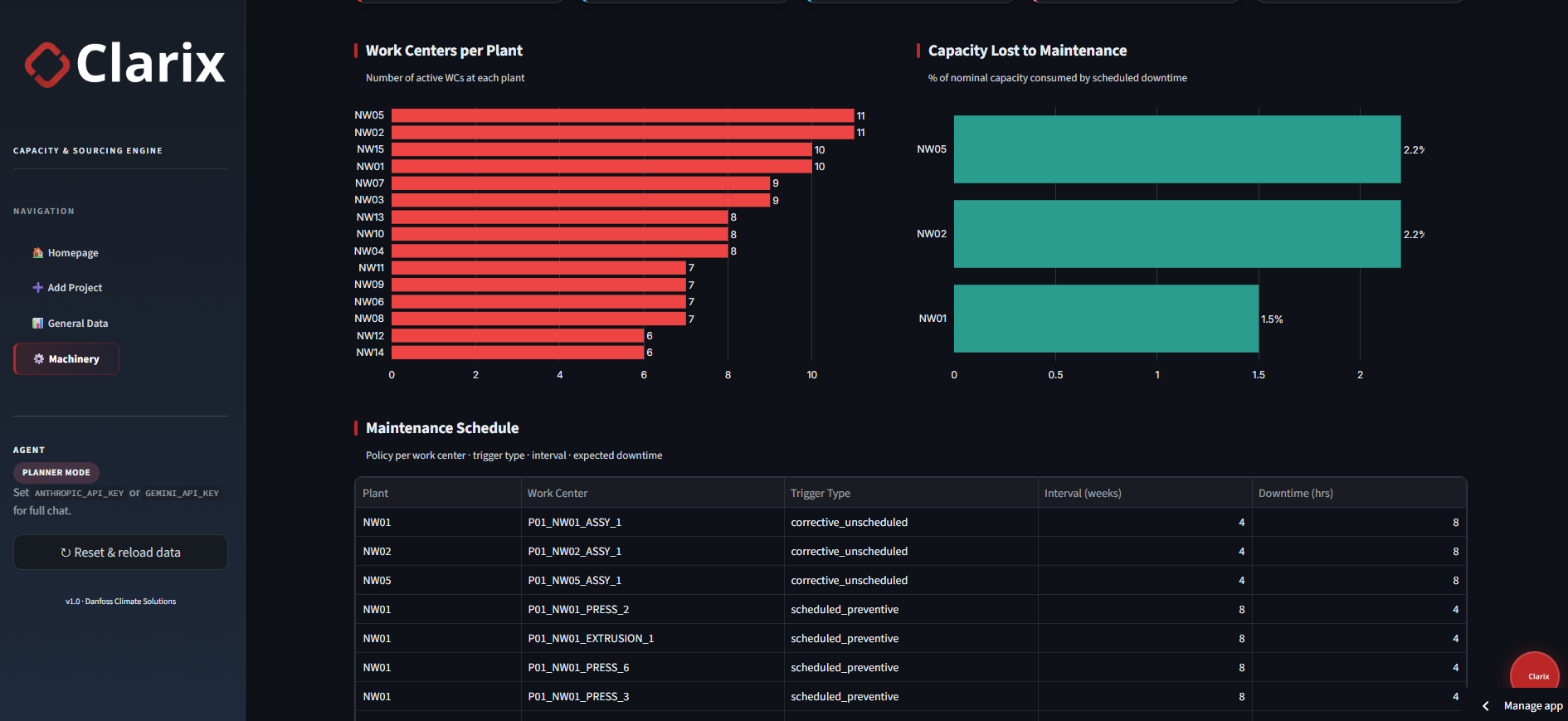
Executive Overview: Portfolio-level KPIs, quarterly revenue, and delivery health.Capacity Planner: Region and project selection with stacked lead time breakdowns across sourcing, production, and transit.Bottlenecks: Ranked work-centre constraints with utilisation thresholds (warning at 85%, critical at 100%).Sourcing & MRP: BOM explosion and ATP-offset back-calculations for raw-material requirements.Ask Clarix: Natural-language queries against the pre-processed canonical tables via the AI agent.
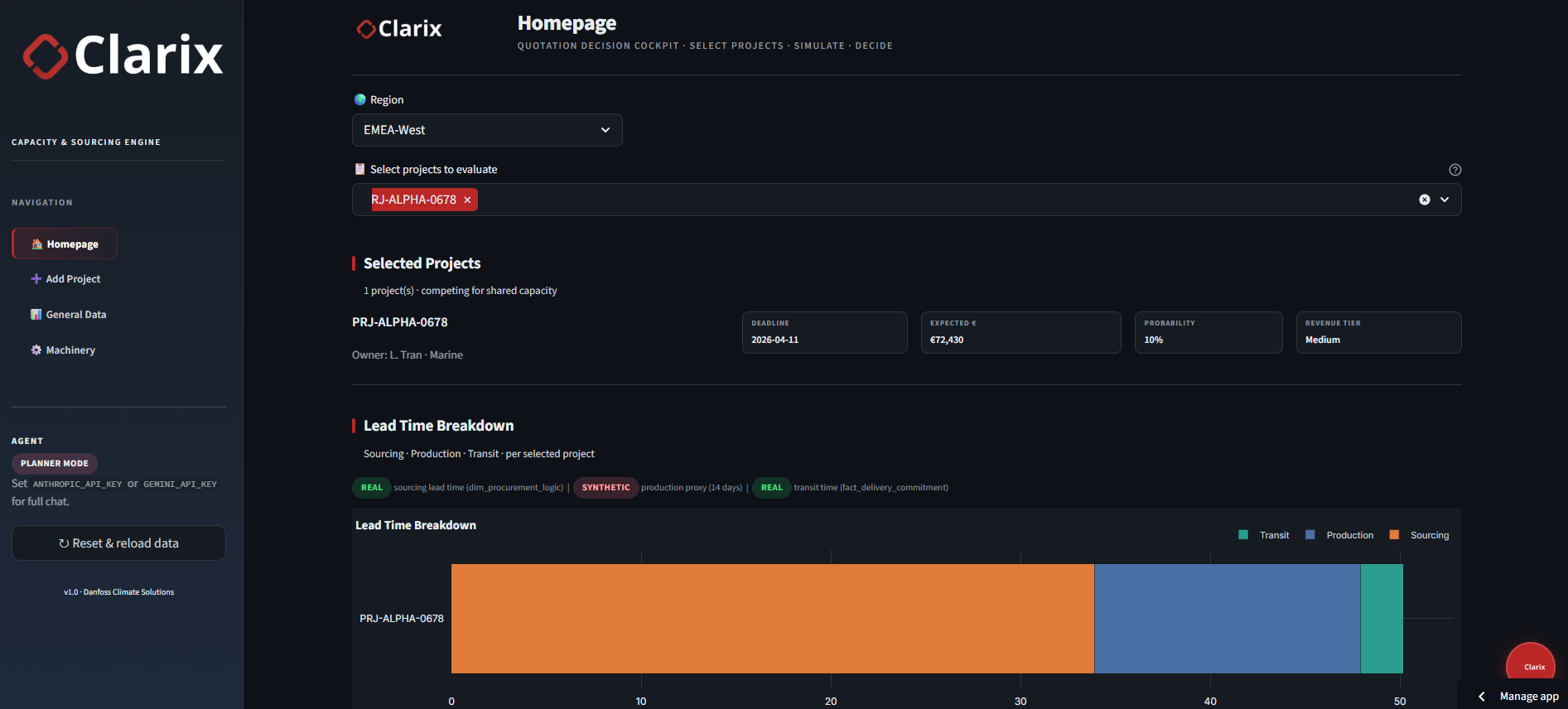
Capacity Planner
Planners select a region (e.g. EMEA-West) and one or more projects to see a stacked lead time breakdown split into sourcing, production, and transit segments. Bottlenecks surface before a delivery date is committed.